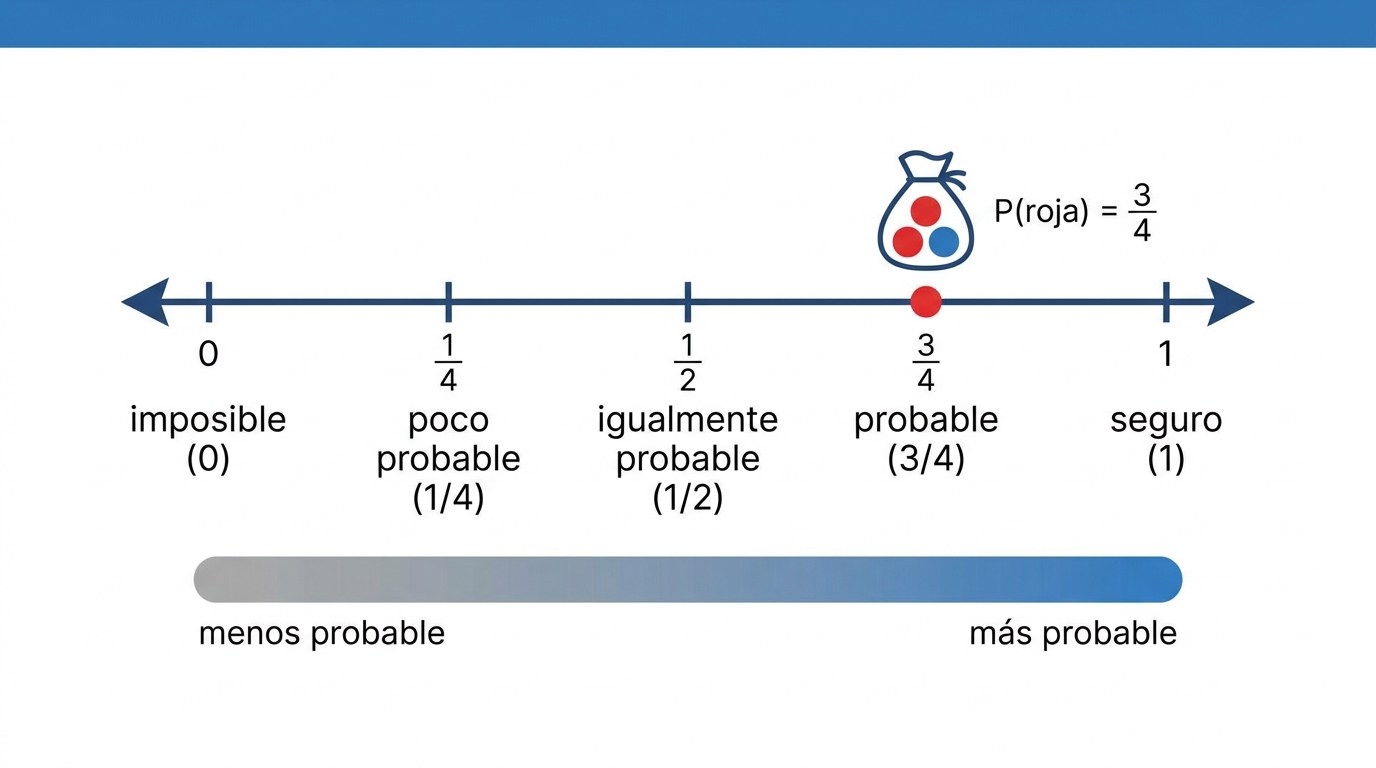
Interpretar y comparar información en distintos gráficos
Un gráfico es una imagen de un conjunto de datos: muestra de un vistazo lo que en una lista de números costaría ver. Pero no todos los gráficos sirven para lo mismo: cada tipo está hecho para responder una pregunta distinta. Elegir o leer mal el gráfico es uno de los errores que la prueba más explota.
- Gráfico de barras: compara cantidades entre categorías distintas (la fruta favorita, los goles por equipo). La altura de cada barra es el dato.
- Gráfico de líneas: muestra cómo cambia una cantidad a lo largo del tiempo (la temperatura durante el día). Sirve para ver tendencias: si sube, baja o se mantiene.
- Gráfico circular (de torta): muestra cómo se reparte un total en partes (qué porcentaje del curso prefiere cada deporte). Todo el círculo es el $100\%$.
- Tallo y hoja: ordena datos numéricos conservando cada valor. El "tallo" es la primera cifra y las "hojas" son las unidades. Permite ver la forma del conjunto sin perder ningún dato.
- Pictograma: usa un ícono que vale una cantidad fija (cada = 5 personas). Hay que multiplicar por el valor del ícono.
Cómo leer un gráfico sin equivocarse
Antes de responder, conviene fijarse en tres cosas que la prueba esconde a propósito: (1) qué representa cada eje (categorías o tiempo en el horizontal; cantidad en el vertical), (2) la escala (¿cada cuadradito vale 1, 5 o 10?; una barra que parece "el doble" puede no serlo si la escala no parte de cero) y (3) las unidades (personas, pesos, grados). En el circular, además, la pregunta suele pedir un porcentaje o comparar dos sectores, no un valor exacto.
Un curso de $40$ estudiantes votó su deporte favorito. El gráfico circular muestra: fútbol $50\%$, vóleibol $25\%$, básquetbol $15\%$ y natación $10\%$. ¿Cuántos eligieron vóleibol?
- Paso 1. El total ($100\%$) son los $40$ estudiantes.
- Paso 2. Vóleibol es el $25\%$, es decir, $\frac{1}{4}$ del total.
- Paso 3. Calculo: $\frac{1}{4}$ de $40 = \frac{40}{4} = 10$ estudiantes.
Comprobación: $50\% + 25\% + 15\% + 10\% = 100\%$, así que los sectores cubren todo el círculo. Error típico: leer el $25\%$ como "$25$ estudiantes". El porcentaje hay que aplicarlo al total.
Las edades de un grupo son: $12, 15, 15, 21, 23, 28, 31$. En tallo y hoja, el tallo son las decenas y la hoja las unidades:
| Tallo | Hojas |
|---|---|
| $1$ | $2\;\;5\;\;5$ |
| $2$ | $1\;\;3\;\;8$ |
| $3$ | $1$ |
La fila "$1 \mid 2\;5\;5$" se lee $12, 15, 15$. La gracia: se ve de un vistazo que casi todos están entre $10$ y $29$, sin perder ningún valor exacto (a diferencia de un gráfico de barras por intervalos).
Confundir qué gráfico responde la pregunta. Si quieres ver cómo varió la temperatura en el día, el de barras o el circular no sirven: necesitas el de líneas (muestra el cambio en el tiempo). Si quieres ver qué parte del total es cada grupo, el circular. Y si quieres comparar categorías independientes, el de barras. Pedir "el porcentaje de cada deporte" a un gráfico de líneas no tiene sentido.
- A) Un gráfico de líneas, porque conecta los valores en el tiempo y deja ver cuándo la temperatura sube o baja.
- B) Un gráfico circular, porque reparte el total de grados del día entre las distintas horas medidas.
- C) Un gráfico de barras, porque permite comparar la altura de cada hora como categorías independientes.
- D) Un diagrama de tallo y hoja, porque ordena todas las temperaturas conservando cada valor exacto.
- A) Tiene razón: el sector de vóleibol marca $25$, así que son $25$ los estudiantes que lo prefieren.
- B) El error es de suma: los porcentajes no llegan a $100\%$, por lo que el gráfico está mal construido.
- C) El sector de vóleibol corresponde a la mitad del curso, es decir, $20$ estudiantes prefieren vóleibol.
- D) El $25\%$ es una fracción del total: hay que aplicarlo a los $40$, y $\frac{1}{4}$ de $40$ son $10$ estudiantes.